提及 HashMap,大家都耳熟能详了,本文不会再讲它的实现原理,只对其中的一些小的实现细节进行罗列。
首先先要明白的两点:
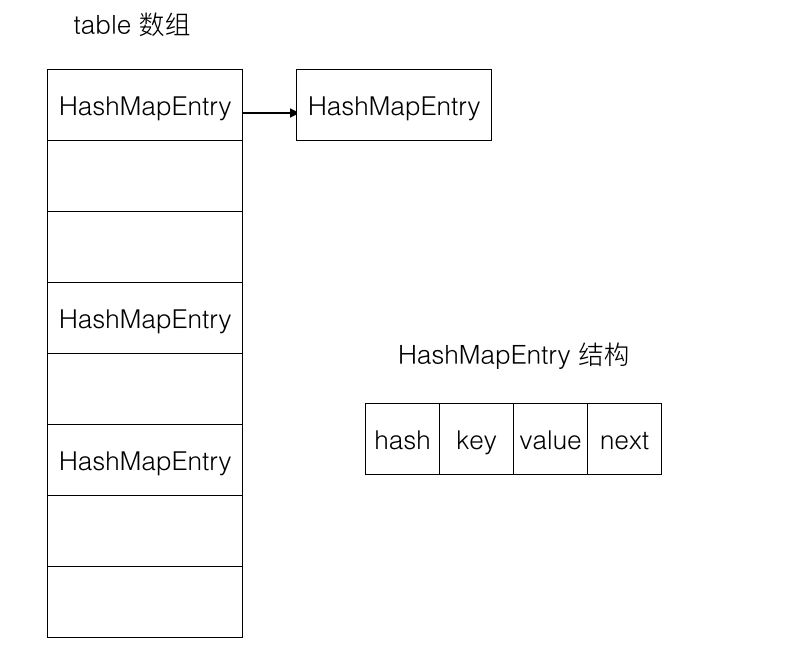
图中的 table 是一个大小为 2n的一维数组,其中存放的是一个个的 HashMapEntry,而 HashMapEntry 是包含了 hash、key 与 value 值及一个指向 HashMapEntry 的 next 指针。
HashMapEntry 在 object 数组中的获取及存放是根据 HashMapEntry 结构的中的 hash 与当前的 table 数组大小一减去已进行与操作的结果来作为相应的索引值( index = (table.length -1 ) & hash)。若在存放的过程中,index 值相同,则会链接当前 entry 的 next 指针上。
只允许放置一个 key 为 null 的元素
知道 HashMap 中允许存放 key 为 null 的元素,纠其原理是因为其中有一个 entryForNullKey 的属性,专门来存放 null 相应的 value 值,再进行 put 和 remove方法的时候,都会对 key 进行判断,若为 null,则会只进行 entryForNullKey相应的更新操作。
1 2 3 4 | |
容量获取算法 roundUpToPowerOfTwo
我们在初始化 HashMap 的时候,可以通过 new HashMap(int capacity)来构造新的 HashMap,而这个参数的值是可以任意填写的,没做任何规范及限制的。(PS:最好根据要存放元素的数量来填写)
但是在 HashMap 的实现当中,而是以大于等于 capacity 并且是 2 的幂数的整数来作为一个新的容量值。修正的算法是通过调用 Collections 类中的 roundUpToPowerOfTwo 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
可以看到这个算法进行了 5 次移位操作,乍一看,一脸懵逼,这是在干嘛?
细细一想啊,我现在要获取一个是 2 的幂数的整数,那其二进制的表现形式就是其最高位为1 ,低位全部为 0;或者其低位全部为 1,只需再对其加 1,即可变成 2 的倍数。
举个栗子:
1 2 3 4 5 6 7 8 9 10 11 | |
其实我们只需将我们的关注点放置其元素为1的最高位上,执行右移操作,紧接着是或操作,最后的结果就是将高位的1,向后涂抹 (smear),全部变为1。
移位5次的原因在于 Java 中的整数是32位的,正好是2的 5次方。
算法刚开始的减一操作,则是为了防止刚开始传入的数字便是 2 的幂数。用来保证最终的结果是大于等于传入的参数的值。
扩容的临界值
HashMap 能够放置元素的最小容量为 4,最大容量为 1 << 30,并且每次扩容之后的容量大小都是 2 的幂数。
什么会扩容呢?在每次调用 HashMap 的 put 方法时,在进行 size++ 时,会与 threshold 进行比较,当超过 threshold时,就会自动扩容。而这个 threshold 的取值为容量的 ¾ ,其值的更新之时,是在一维数组 table 根据乘以2的容量,申请空间之时,即 makeTable 方法:
1 2 3 4 5 6 7 8 9 10 11 | |
这里主要研究一下这个获取容量为 ¾ 的算法,将 newCapacity 右移1位,即获取的是 1/2;右移2位,即获取 1/4;另外再加上 newCapacity 为2的倍数,所以这里的 ¾ 毫无破绽。
扩容 * 2实现中的元素转移
假如我当前 HashMap 中的容量(capacity)为8,在执行元素的获取及存放是,都是先拿元素的 hash 值,跟 capacity - 1 即 7,对应的二进制为 111,执行与操作,获取的结果即为对应所存放数组中的索引。
而当 HashMap 在进行扩容 * 2 之后,元素的获取也要满足上面的方法,那在扩容的时候,就要先前数组到新数组的赋值,那它这个重新索引的算法是怎么进行的呢?
在执行 doubleCapacity方法时候,会进行这个操作:
1 2 3 4 5 6 7 8 9 10 11 | |
因 oldCapacity 为2的幂数,获取到的 highBit 也是 2 的幂数。若是 e.hash 对应在 oldCapacity 的高位也是相同的 1,则 newTable的索引 j | highBit则是相当于 j 加上了 2 的幂数,即 j | highBit 相对于 newCapacity 来说,从前半段移动到后半段;若是 e.hash 对应在 oldCapacity 的高位不为1,则获取到 highBit 为零,则相应旧数组迁移至新数组的索引位置还是维持原样。
简化上面的公式:
公式一: oldIndex = ( 2n -1) | hash
公式二: hash & 2n | oldIndex = newIndex
可知新的 newIndex 同时也满足:
公式三: newIndex = (2n+1 - 1) | hash
若是我们将公式一和公式三都代入公式二中,消除 oldIndex 和 newIndex 可得到:
公式四: hash & (2n -1) | (hash & 2n) = hash & ( 2n+1 - 1)
这里发现这个公式,很是符合结合律,即:
( a & x ) | ( a & y ) = a & ( x | y )
不要问我怎么证明这个公式是对的。(我是问了个妹子,妹子直接告诉不要纠结公式,直接读字面量,即与或操作,就可发现这个公式是正确的。)
这样的话,将上面的公式执行结合律的话,可得公式四的左边:
hash & ((2n -1) | 2n ) = hash & ( 2n+1 - 1)
确定是跟公式四的右半部分相等。至此,可证明这个扩容移位的操作是毫无破绽的,不过一时半会理解起来还是颇为费劲的,也不得不感叹作者的强大。
Hash 值的生成
在进行元素的存放及获取时,都会获取元素的 hash 值,(即是 key 的 hash值),而一个好的 HashMap,应该是元素均匀地放置在数组中,而不应该大量地出现簇拥现象,(即对应的 HashMapEntry 的 next 指针不为空)。所以仅仅依靠原始的 key 的 hash 值,则是不靠谱的。所以 HashMap 的算法都会进行二次 hash,但我发现 java 中的版本 跟 android 版本实现完全不一致:
- Android的实现(以 Android API 23 为例)
这里真正的实现是在
Collections类中:
1 2 3 4 5 6 7 8 9 10 | |
这个算法看的是一脸懵逼,若是有哪位大神看懂了,希望能够指点一下小弟。这里可去参看注释中提到的 Wang/Jenkins hash,这里是借鉴这位大神的实现。算法最终达到的效果就是一个网友提到的“崩坏性”,即微小的改动,也会触发结果的大变样。
- Java的实现 (以 JDK 1.8 为例)
1 2 3 4 | |
明显地看出它这里处理就相当简单了,只将高位进行后移16位,然后进行异或就结束了。不过官方文档给出的说法是,因为其 table 大小是 2n ,其实发生碰撞的概率很小,另外在 1.8 中碰撞的链表已经修改为了树结构,所以这里是针对速度、实用及位扩展操作复杂度的一个权衡。
线程同步
另外需要谨记的是,HashMap 不是线程安全的,若出现多线程访问的问题,需要实用 Collections.synchronizedMap(Map<K, V> map) 方法来对 map 再进行一次包装。不过其返回的数据结构 SynchronizedMap 也是很简单的,采用组合的方式持有 map,然后针对 map 的每个操作,都加上了同步块。
至此,HashMap 应该了然于胸了,若是小伙伴还有什么疑问的话,欢迎一起交流。
