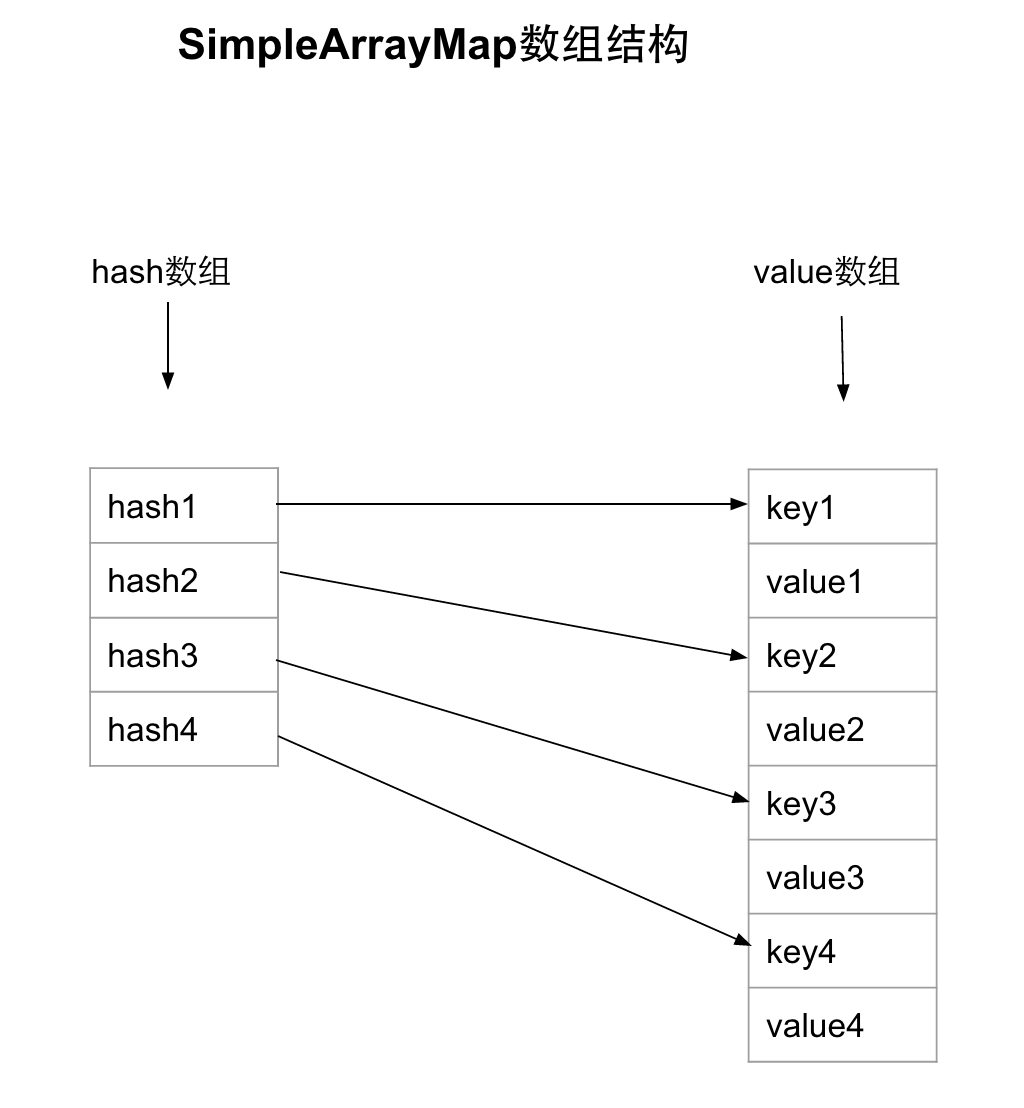
/** * Create a new empty ArrayMap. The default capacity of an array map is 0, and * will grow once items are added to it. */publicSimpleArrayMap(){mHashes=ContainerHelpers.EMPTY_INTS;mArray=ContainerHelpers.EMPTY_OBJECTS;mSize=0;}
指定初始大小
123456789101112
/** * Create a new ArrayMap with a given initial capacity. */publicSimpleArrayMap(intcapacity){if(capacity==0){mHashes=ContainerHelpers.EMPTY_INTS;mArray=ContainerHelpers.EMPTY_OBJECTS;}else{allocArrays(capacity);}mSize=0;}
通过SimpleArrayMap赋值
123456789
/** * Create a new ArrayMap with the mappings from the given ArrayMap. */publicSimpleArrayMap(SimpleArrayMapmap){this();if(map!=null){putAll(map);}}
3.释放
1234567891011
/** * Make the array map empty. All storage is released. */publicvoidclear(){if(mSize!=0){freeArrays(mHashes,mArray,mSize);mHashes=ContainerHelpers.EMPTY_INTS;mArray=ContainerHelpers.EMPTY_OBJECTS;mSize=0;}}
/** * Add a new value to the array map. * @param key The key under which to store the value. <b>Must not be null.</b> If * this key already exists in the array, its value will be replaced. * @param value The value to store for the given key. * @return Returns the old value that was stored for the given key, or null if there * was no such key. */publicVput(Kkey,Vvalue){finalinthash;intindex;if(key==null){// 查找key为null的情况hash=0;index=indexOfNull();}else{hash=key.hashCode();index=indexOf(key,hash);}if(index>=0){// 数组中存在相同的key,则更新并返回旧的值index=(index<<1)+1;finalVold=(V)mArray[index];mArray[index]=value;returnold;}index=~index;if(mSize>=mHashes.length){// 当容量不够时,需要建立一个新的数组,来进行扩容操作。finalintn=mSize>=(BASE_SIZE*2)?(mSize+(mSize>>1)):(mSize>=BASE_SIZE?(BASE_SIZE*2):BASE_SIZE);if(DEBUG)Log.d(TAG,"put: grow from "+mHashes.length+" to "+n);finalint[]ohashes=mHashes;finalObject[]oarray=mArray;allocArrays(n);if(mHashes.length>0){if(DEBUG)Log.d(TAG,"put: copy 0-"+mSize+" to 0");System.arraycopy(ohashes,0,mHashes,0,ohashes.length);System.arraycopy(oarray,0,mArray,0,oarray.length);}freeArrays(ohashes,oarray,mSize);}// 将index之后的数据进行后移if(index<mSize){if(DEBUG)Log.d(TAG,"put: move "+index+"-"+(mSize-index)+" to "+(index+1));System.arraycopy(mHashes,index,mHashes,index+1,mSize-index);System.arraycopy(mArray,index<<1,mArray,(index+1)<<1,(mSize-index)<<1);}// 赋值给index位置上hash值mHashes[index]=hash;// 更新array数组中对应的key跟value值。mArray[index<<1]=key;mArray[(index<<1)+1]=value;mSize++;returnnull;}
/** * Retrieve a value from the array. * @param key The key of the value to retrieve. * @return Returns the value associated with the given key, * or null if there is no such key. */publicVget(Objectkey){finalintindex=indexOfKey(key);returnindex>=0?(V)mArray[(index<<1)+1]:null;}
/** * Remove an existing key from the array map. * @param key The key of the mapping to remove. * @return Returns the value that was stored under the key, or null if there * was no such key. */publicVremove(Objectkey){finalintindex=indexOfKey(key);if(index>=0){returnremoveAt(index);}returnnull;}
/** * Remove the key/value mapping at the given index. * @param index The desired index, must be between 0 and {@link #size()}-1. * @return Returns the value that was stored at this index. */publicVremoveAt(intindex){finalObjectold=mArray[(index<<1)+1];if(mSize<=1){// Now empty.if(DEBUG)Log.d(TAG,"remove: shrink from "+mHashes.length+" to 0");freeArrays(mHashes,mArray,mSize);mHashes=ContainerHelpers.EMPTY_INTS;mArray=ContainerHelpers.EMPTY_OBJECTS;mSize=0;}else{// 满足条件,对数组进行加入缓存的操作。if(mHashes.length>(BASE_SIZE*2)&&mSize<mHashes.length/3){// Shrunk enough to reduce size of arrays. We don't allow it to// shrink smaller than (BASE_SIZE*2) to avoid flapping between// that and BASE_SIZE.finalintn=mSize>(BASE_SIZE*2)?(mSize+(mSize>>1)):(BASE_SIZE*2);if(DEBUG)Log.d(TAG,"remove: shrink from "+mHashes.length+" to "+n);finalint[]ohashes=mHashes;finalObject[]oarray=mArray;allocArrays(n);mSize--;if(index>0){if(DEBUG)Log.d(TAG,"remove: copy from 0-"+index+" to 0");System.arraycopy(ohashes,0,mHashes,0,index);System.arraycopy(oarray,0,mArray,0,index<<1);}if(index<mSize){if(DEBUG)Log.d(TAG,"remove: copy from "+(index+1)+"-"+mSize+" to "+index);System.arraycopy(ohashes,index+1,mHashes,index,mSize-index);System.arraycopy(oarray,(index+1)<<1,mArray,index<<1,(mSize-index)<<1);}}else{mSize--;if(index<mSize){if(DEBUG)Log.d(TAG,"remove: move "+(index+1)+"-"+mSize+" to "+index);System.arraycopy(mHashes,index+1,mHashes,index,mSize-index);System.arraycopy(mArray,(index+1)<<1,mArray,index<<1,(mSize-index)<<1);}mArray[mSize<<1]=null;mArray[(mSize<<1)+1]=null;}}return(V)old;}
/** * Returns the index of a key in the set. * * @param key The key to search for. * @return Returns the index of the key if it exists, else a negative integer. */publicintindexOfKey(Objectkey){returnkey==null?indexOfNull():indexOf(key,key.hashCode());}
intindexOf(Objectkey,inthash){finalintN=mSize;// Important fast case: if nothing is in here, nothing to look for.if(N==0){return~0;}intindex=ContainerHelpers.binarySearch(mHashes,N,hash);// If the hash code wasn't found, then we have no entry for this key.if(index<0){returnindex;}// If the key at the returned index matches, that's what we want.if(key.equals(mArray[index<<1])){returnindex;}// Search for a matching key after the index.intend;for(end=index+1;end<N&&mHashes[end]==hash;end++){if(key.equals(mArray[end<<1]))returnend;}// Search for a matching key before the index.for(inti=index-1;i>=0&&mHashes[i]==hash;i--){if(key.equals(mArray[i<<1]))returni;}// Key not found -- return negative value indicating where a// new entry for this key should go. We use the end of the// hash chain to reduce the number of array entries that will// need to be copied when inserting.return~end;}
intindexOfNull(){finalintN=mSize;// Important fast case: if nothing is in here, nothing to look for.if(N==0){return~0;}intindex=ContainerHelpers.binarySearch(mHashes,N,0);// If the hash code wasn't found, then we have no entry for this key.!if(index<0){returnindex;}// If the key at the returned index matches, that's what we want.if(null==mArray[index<<1]){returnindex;}// Search for a matching key after the index.intend;for(end=index+1;end<N&&mHashes[end]==0;end++){if(null==mArray[end<<1])returnend;}// Search for a matching key before the index.for(inti=index-1;i>=0&&mHashes[i]==0;i--){if(null==mArray[i<<1])returni;}// Key not found -- return negative value indicating where a// new entry for this key should go. We use the end of the// hash chain to reduce the number of array entries that will// need to be copied when inserting.return~end;}
// This is Arrays.binarySearch(), but doesn't do any argument validation.staticintbinarySearch(int[]array,intsize,intvalue){intlo=0;inthi=size-1;while(lo<=hi){intmid=(lo+hi)>>>1;intmidVal=array[mid];if(midVal<value){lo=mid+1;}elseif(midVal>value){hi=mid-1;}else{returnmid;// value found}}return~lo;// value not present}
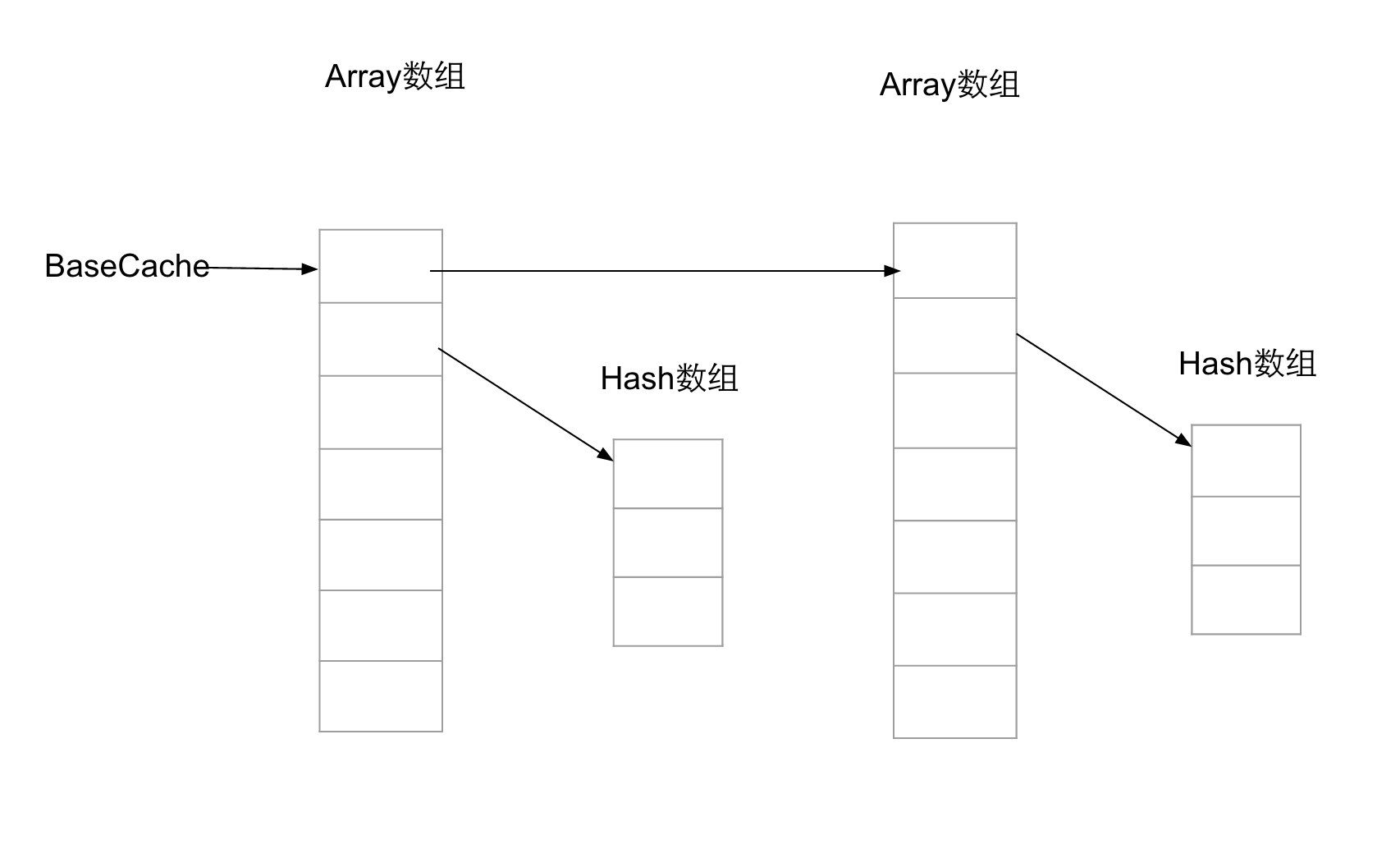
/** * The minimum amount by which the capacity of a ArrayMap will increase. * This is tuned to be relatively space-efficient. */privatestaticfinalintBASE_SIZE=4;/** * Maximum number of entries to have in array caches. */privatestaticfinalintCACHE_SIZE=10;/** * Caches of small array objects to avoid spamming garbage. The cache * Object[] variable is a pointer to a linked list of array objects. * The first entry in the array is a pointer to the next array in the * list; the second entry is a pointer to the int[] hash code array for it. */staticObject[]mBaseCache;staticintmBaseCacheSize;staticObject[]mTwiceBaseCache;staticintmTwiceBaseCacheSize;
privatestaticvoidfreeArrays(finalint[]hashes,finalObject[]array,finalintsize){if(hashes.length==(BASE_SIZE*2)){synchronized(ArrayMap.class){if(mTwiceBaseCacheSize<CACHE_SIZE){array[0]=mTwiceBaseCache;array[1]=hashes;for(inti=(size<<1)-1;i>=2;i--){array[i]=null;}mTwiceBaseCache=array;mTwiceBaseCacheSize++;if(DEBUG)Log.d(TAG,"Storing 2x cache "+array+" now have "+mTwiceBaseCacheSize+" entries");}}}elseif(hashes.length==BASE_SIZE){synchronized(ArrayMap.class){if(mBaseCacheSize<CACHE_SIZE){array[0]=mBaseCache;array[1]=hashes;for(inti=(size<<1)-1;i>=2;i--){array[i]=null;}mBaseCache=array;mBaseCacheSize++;if(DEBUG)Log.d(TAG,"Storing 1x cache "+array+" now have "+mBaseCacheSize+" entries");}}}}
privatevoidallocArrays(finalintsize){if(size==(BASE_SIZE*2)){synchronized(ArrayMap.class){if(mTwiceBaseCache!=null){finalObject[]array=mTwiceBaseCache;mArray=array;mTwiceBaseCache=(Object[])array[0];mHashes=(int[])array[1];array[0]=array[1]=null;mTwiceBaseCacheSize--;if(DEBUG)Log.d(TAG,"Retrieving 2x cache "+mHashes+" now have "+mTwiceBaseCacheSize+" entries");return;}}}elseif(size==BASE_SIZE){synchronized(ArrayMap.class){if(mBaseCache!=null){finalObject[]array=mBaseCache;mArray=array;mBaseCache=(Object[])array[0];mHashes=(int[])array[1];array[0]=array[1]=null;mBaseCacheSize--;if(DEBUG)Log.d(TAG,"Retrieving 1x cache "+mHashes+" now have "+mBaseCacheSize+" entries");return;}}}mHashes=newint[size];mArray=newObject[size<<1];}